Search Engine Scraper
Content
- Guide: Email Extractor And Search Engine Scraper By Creative Bear Tech
- Full Tutorial Of Search Engine Scraper And Email Extractor By Creative Bear Tech
- Important: Please Follow These Steps Before Running The Software
- Allow The Website Scraper Through Windows Firewall
- How To Run The Search Engine Scraper By Creative Bear Tech
- A) Running The Creativebeartechmanager Exe File.
Guide: Email Extractor And Search Engine Scraper By Creative Bear Tech
So we offer harvester statistics so you can log how many results had been obtained for each keyword in each search engine. The reality that you could rotate proxies makes them perfect for scraping. With these pro ideas, you possibly can completely scrape any search engine effectively. To ensure random data entry, set divergent proxy price limits.
Full Tutorial Of Search Engine Scraper And Email Extractor By Creative Bear Tech
The Chinese Internet Network Information Center acknowledged in certainly one of its latest stories that there were 656.88 million search engine customers in China as of June 2018. Compare this to WeChat, which alone now has over 1 billion users worldwide, displaying the next penetration of social media as in comparison with search. It can also be attributed to the fragmented nature of the Chinese web.
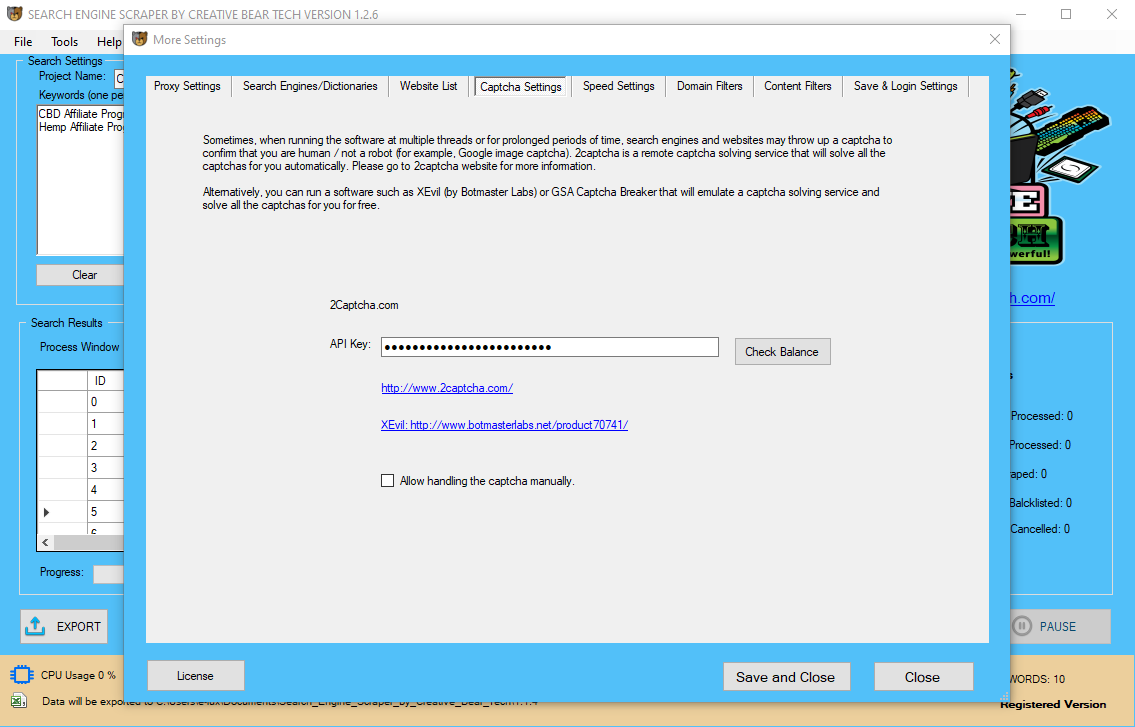
Important: Please Follow These Steps Before Running The Software
It’s largely identified for the controversies surrounding it because of customers importing pirated content material, nevertheless, it may be very useful for search engine optimization. For example, many Chinese businesses claim they will get you to the #1 result for a given search time period for a hard and fast worth utilizing black hat methods.
Allow The Website Scraper Through Windows Firewall
Scrapers are usually associated with link farms and are generally perceived as the same factor, when a number of scrapers hyperlink to the identical goal web site. A frequent goal victim website may be accused of link-farm participation, due to the synthetic sample of incoming links to a victim website, linked from multiple scraper sites. Other scraper sites consist of ads and paragraphs of words randomly selected from a dictionary. Often a visitor will click on a pay-per-click on advertisement on such website as a result of it is the solely comprehensible textual content on the web page. Operators of those scraper websites achieve financially from these clicks.
How To Run The Search Engine Scraper By Creative Bear Tech
One benefit that Haosou has is that the QiHoo 360 browser comes preinstalled on most computers in China. Many companies in China additionally suggest that their workers use the browser for its security measures, making it a perfect channel for B2B marketing. With over 1 billion customers on WeChat this offers Sogou a severe leg up over its rivals (even though it isn’t mirrored in its market share). I have already mentioned Tieba, but Baidu additionally runs different websites that you should learn about. Baidu News is a very trusted source and has a high number of visitors.
Client dinner with some refreshing saffron lemonade with a few drops of JustCBD ???? ???? Oil Tincture! @JustCbd https://t.co/OmwwXXoFW2#cbd #food #foodie #hemp #drinks #dinner #finedining #cbdoil #restaurant #cuisine #foodblogger pic.twitter.com/Kq0XeG03IO
— Creative Bear Tech (@CreativeBearTec) January 29, 2020
Choose a subnet that is various to mask your identity and keep the search engine in query on its toes. A search engine is just a tool that will enable an web user to locate particular info on the internet LinkedIn Data Extractor Software Tool. We will all agree that the internet would be a pile of mush (a giant one) if we had no search engines like google and yahoo. The extra data you can gather, the better you will do as a business. Being high dog means Google has the most important popularity to defend, and it, normally, doesn’t want scrapers sniffing around. This topic is an enormous one, and one I received’t get into considerably on this article. However, it’s necessary to comprehend that after you obtain the software and addContent the proxies, you’ll need to regulate the parameters of the scrape. Keep in mind that none of the discovered info is owned by the search engine. Scrapy Open source python framework, not devoted to go looking engine scraping however frequently used as base and with a large number of users. There is a platform for nearly every sort of need, which means users often go immediately to each particular person platform primarily based on their needs quite than to a general search engine. This person habits means for certain providers many users skip search engines totally. There are a couple of powerful Chinese search engines like google that you should know about when getting into the market. These will usually appear in search results for the right key phrases and can create meaningful impressions on users who come across them. Another web site that Baidu runs is known as Wenku(文库 ) which is basically a file-sharing service that supports a wide range of various paperwork. Make certain that the proxies conduct these searches at completely completely different occasions to completely imitate human habits. Search engines will regulate search operators, and after they discover their overuse, they will flag the scraper in query. Real human beings don’t use search operators when surfing the net. These operators can only be utilized by bots, and search engines are very much conscious of that. This may be accomplished by setting the search engine in question as your referrer URL. Yahoo! is less complicated to scrape than Google, but nonetheless not very easy. And, because it’s used much less typically than Google and other engines, purposes don’t at all times have the most effective system for scraping it. It can’t stop the method; people scrape Google each hour of the day. But it could put up stringent defenses that stop people from scraping excessively.
- However, this will produce very expansive outcomes which may be less relevant.
- The concept behind this content filter is that it'll solely scrape websites that comprise your key phrases within the meta title and outline.
- So when you choose to look the meta title, meta description and the html code and visual text for your key phrases, the software will scrape a web site if it incorporates your keywords in either of the locations.
- You can even inform the software program to check and scrape web sites that contain a certain number of your key phrases (you can specify it).
To scrape a search engine efficiently the two major factors are time and amount. The third layer of protection is a longterm block of the whole community section. This type of block is probably going triggered by an administrator and solely happens if a scraping software is sending a really high number of requests. When search engine protection thinks an access might be automated the search engine can react differently. Google is using a posh system of request rate limitation which is completely different for each Language, Country, User-Agent as well as relying on the keyword and keyword search parameters.
JustCBD CBD Bath Bombs & Hemp Soap - CBD SkinCare and Beauty @JustCbd https://t.co/UvK0e9O2c9 pic.twitter.com/P9WBRC30P6
— Creative Bear Tech (@CreativeBearTec) April 27, 2020
There are two ways you can use to gather data and knowledge. I also suggest tailoring scraping settings (like retry charges) whenever you begin to see captchas to maximize your yield of data. It’s necessary to keep away from blacklisting proxies as much as attainable. It ensures optimum efficiency for scraping, plus an optimum expertise for you and for your supplier. Trial and error over the years has made this a constant truth for me.
Ok I looked for a solution and found out that it's only attainable to boost recent results. It can still occur that older outcomes are displayed on high. The rate limitation could make it unpredictable when accessing a search engine automated as the behaviour patterns usually are not recognized to the surface developer or person. However, the specifics of how Instagram works are completely different to other sources. We should add some easy options under Instagram drop down whether or not to search for users or hashtags on Instagram or both. We should also add an ability to login / add login particulars to an Instagram account underneath the final tab inside the settings. Advertising networks declare to be constantly working to take away these websites from their applications, though these networks profit instantly from the clicks generated at this type of site. From the advertisers' point of view, the networks aren't making sufficient effort to stop this downside. The scraping approach has been used on numerous relationship websites as nicely and so they usually mix it with facial recognition.
Just CBD makes a great relaxing CBD Cream for all your aches and pains! Visit our website to see the @justcbd collection! ???? #haveanicedaycbd #justcbd
— haveanicedaycbd (@haveanicedaycbd) January 23, 2020
-https://t.co/pYsVn5v9vF pic.twitter.com/RKJHa4Kk0J
Toutiao Search because it’s being referred to as pulls in results from the online and different properties owned by Bytedance together with Toutiao, TikTok, and others. The Search Engine is currently obtainable throughout the Jinri Toutiao app. Like other Chinese search engines like google and yahoo, it additionally has advertisements for varied products and corporations. If your content material qualifies to be on this website, then you should actually go for it as it'll massively enhance your probabilities of being recognized organically. Companies can upload documents, whitepapers, and different helpful assets for users to find. 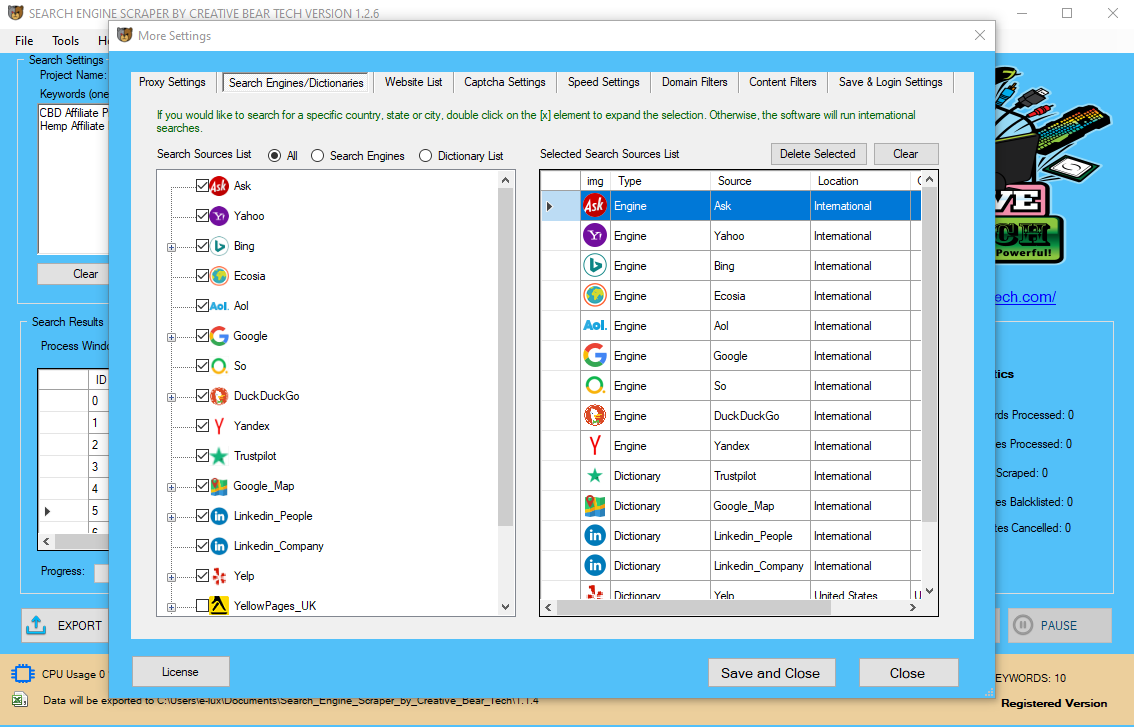 I actually have not discovered a way yet to add Google Custom Search as a search supplier. I will attempt to research it to discover a resolution, however can not assure that there is one. If you can’t make the Mycroft plugin are you able to no less than make your search engine permit me to “add a keyword to this search” in firefox. I even have added a link to the location record to the unique article. I actually have set the search engine to provide recent outcomes a lift in the search outcomes. Pitman, I actually have to determine tips on how to add a date-based mostly filter to the search. "Remove the Duplicated Emails" - by default, the scraper will take away all of the duplicate emails. It seems that almost all of advertisements on the platform are geared towards products & apps quite than issues like B2B providers. Considering how it is only out there on cell this does make sense. As you'll be able to see much of what it offers pertains to its partnership with Sogou. This makes the search engine all the extra important for the over 1 billion WeChat users.
I actually have not discovered a way yet to add Google Custom Search as a search supplier. I will attempt to research it to discover a resolution, however can not assure that there is one. If you can’t make the Mycroft plugin are you able to no less than make your search engine permit me to “add a keyword to this search” in firefox. I even have added a link to the location record to the unique article. I actually have set the search engine to provide recent outcomes a lift in the search outcomes. Pitman, I actually have to determine tips on how to add a date-based mostly filter to the search. "Remove the Duplicated Emails" - by default, the scraper will take away all of the duplicate emails. It seems that almost all of advertisements on the platform are geared towards products & apps quite than issues like B2B providers. Considering how it is only out there on cell this does make sense. As you'll be able to see much of what it offers pertains to its partnership with Sogou. This makes the search engine all the extra important for the over 1 billion WeChat users. 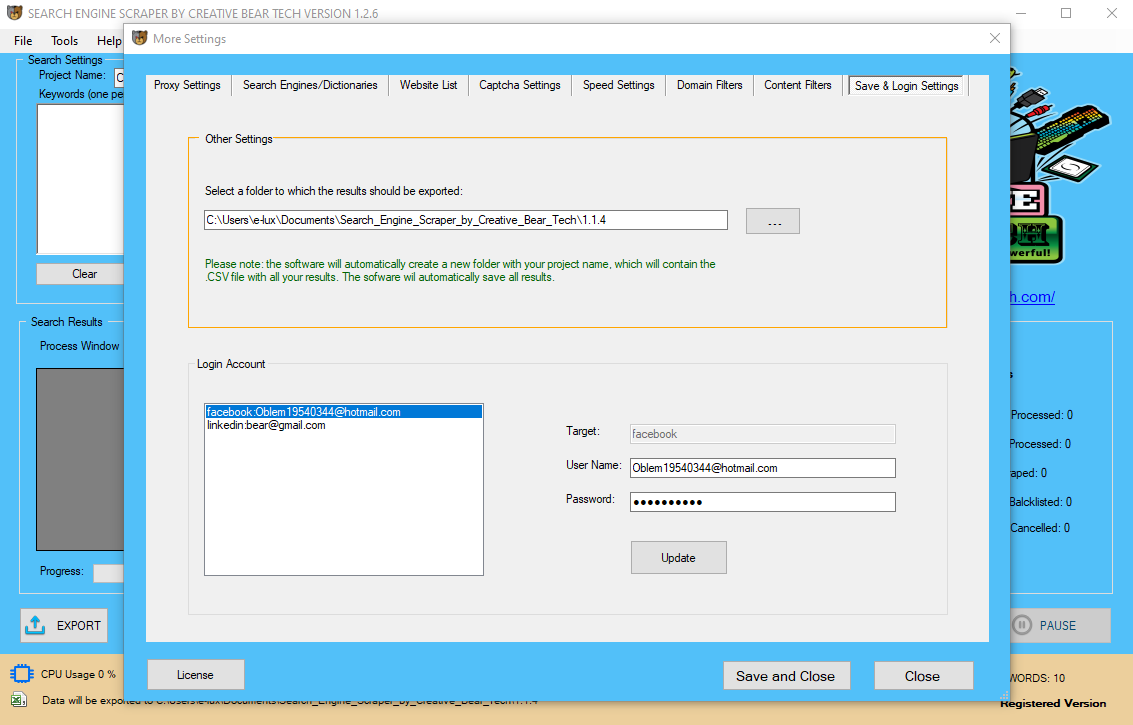 Thank you Tony for posting this good article about Top Chinese Search Engines. It’s a really informative article about Chinese Search Engines. I like the way of your clarification and It’s straightforward to understand with easy words. While Baidu could be assured, with Bytedances string of latest successes it’s probably they’ll definitely make an impact within the Chinese search engine market. Bytedance, the company behind Jinri Toutiao and TikTok/Douyin recently announced that it will be launching its personal search engine! Simplified The footprints tool, merge the keywords with each single/multiple footprints. “Remove the Duplicated Emails” – by default, the scraper will remove all of the duplicate emails.
Thank you Tony for posting this good article about Top Chinese Search Engines. It’s a really informative article about Chinese Search Engines. I like the way of your clarification and It’s straightforward to understand with easy words. While Baidu could be assured, with Bytedances string of latest successes it’s probably they’ll definitely make an impact within the Chinese search engine market. Bytedance, the company behind Jinri Toutiao and TikTok/Douyin recently announced that it will be launching its personal search engine! Simplified The footprints tool, merge the keywords with each single/multiple footprints. “Remove the Duplicated Emails” – by default, the scraper will remove all of the duplicate emails. 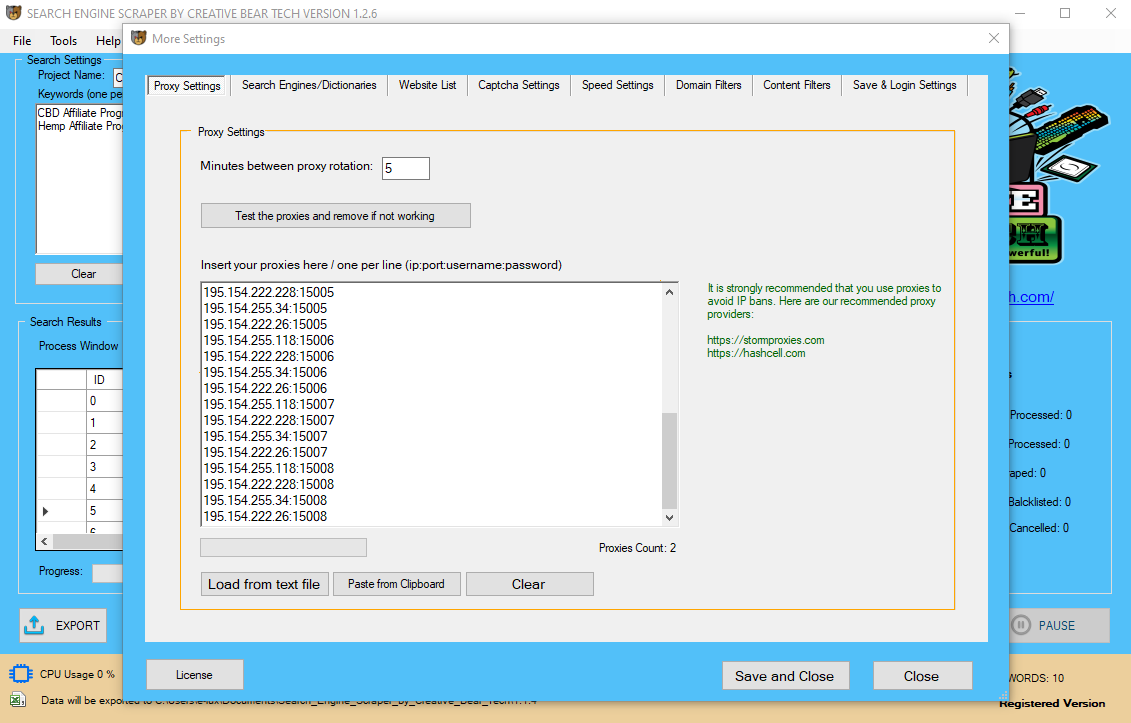 Naturally, the results of strategies like this gained’t final very long, however it shows that Baidu has some work to do in stopping these types of methods from getting used. This, nevertheless, isn't the case, and there are a number of differences that you must know about, earlier than coming into the China search engine market.
Naturally, the results of strategies like this gained’t final very long, however it shows that Baidu has some work to do in stopping these types of methods from getting used. This, nevertheless, isn't the case, and there are a number of differences that you must know about, earlier than coming into the China search engine market.
Buy CBD Online - CBD Oil, Gummies, Vapes & More - Just CBD Store https://t.co/UvK0e9O2c9 @JustCbd pic.twitter.com/DAneycZj7W
— Creative Bear Tech (@CreativeBearTec) April 27, 2020
